Classifying Memory Access Patterns for Prefetching
From AcaWiki
Citation: Grant Ayers, Heiner Litz, Christos Kozyrakis, Partha Ranganathan (2020/05) Classifying Memory Access Patterns for Prefetching. Architectural Support for Programming Languages and Operating Systems (RSS)
DOI (original publisher): 10.1145/3373376.3378498
Semantic Scholar (metadata): 10.1145/3373376.3378498
Sci-Hub (fulltext): 10.1145/3373376.3378498
Internet Archive Scholar (search for fulltext): Classifying Memory Access Patterns for Prefetching
Download: https://dl.acm.org/doi/10.1145/3373376.3378498
Tagged: Computer Science
(RSS) computer architecture (RSS)
Summary
Placeholder
Theoretical and Practical Relevance
This paper characterizes kinds of prefetching and provides a tool which can determine the theoretical speedup of each kind.
Elsewhere
Problem
- Many important problems are memory bound.
- Caching can only partially address this, due to mandatory misses (conflict, cold, capacity, and coherence misses).
- We need prefetching to address this.
- Prior work was either performant (nextline, stride, correlation) or general (large-table, run-ahead execution, static compiler), not both.
- Architects would like to answer:
- How much performance can we expect from this prefetcher?
- How much opportunity is left on the table?
Solution
- Look at x86 machine code, find DFG for the address, and classify loads into categories:
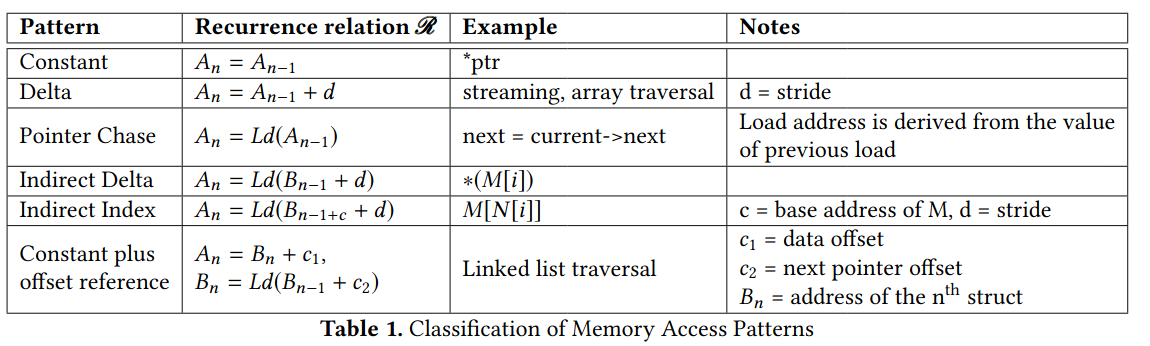
- x86 was chosen because of its ubiquity in the domain.
- From this, we can tell how complex it would be to compute the address, and how far in advance one can start that computation.
- Ideal candidates for prefetching cause many misses (dark), don't take long to compute their address (leftwards), and have plenty of time to do the prefetching (upwards).
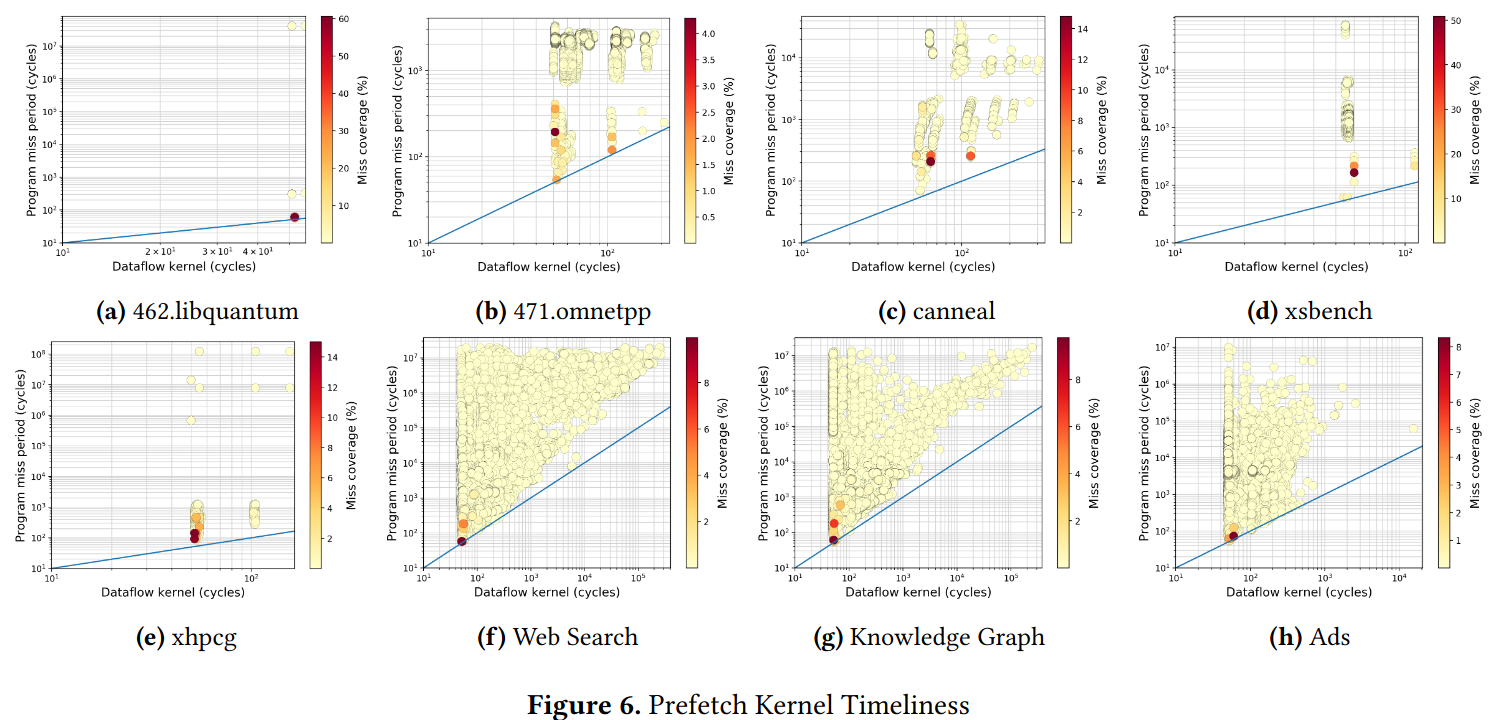
- Authors show that this analysis can tell them how good a certain prefetcher will be, and what the theoretical maximum speedup due to prefetching is.



Discussion
- Prefetching is similar to the older idea of decoupled access/execute. The pretfetching unit is like the access-unit.
- This is especially true of run-ahead prefetching.
- The authors choose to analyze the x86 machine code.
- This looses some semantic information, but it gains generality. Everything in their domain is x86.
- Perhaps future work could do this in LLVM. It would have more semantic information, and it could reuse existing tooling for manipulating the DFG.